
本文档由北京小芽科技翻译,原文来自于ROBOTIS官方技术文档。
机器学习是一种数据分析技术,教计算机识别人和动物的自然现象–通过经验学习。机器学习有三种类型:监督学习、无监督学习、强化学习。
这个应用是用DQN(Deep Q-Learning)进行强化学习。强化学习关注的是软件代理应该如何在一个环境中采取行动,以便使一些累积奖励的概念最大化。
电子手册中的内容可能会在没有事先通知的情况下进行更新。因此,一些视频可能与电子手册中的内容有所不同。
这显示了TurtleBot3在 gazebo中的强化学习。这个强化学习应用了LDS的DQN(Deep Q-Learning)算法。
我们正在准备一个四步强化学习的教程。
9.1 软件设置
要做这个教程,你需要用Ubuntu 16.04和ROS1 Kinetic安装Tensorflow、Keras和Anaconda。
9.1.1 Anaconda
你可以下载 Anaconda 5.2.0 用于Python 2.7版本。
下载完Andaconda后,进入下载文件所在的目录,输入以下命令。
在终端输入 “yes”,查看并接受许可条款。
同时在.basrhc文件中把Anaconda2的安装位置添加到PATH。
1 | $ bash Anaconda2-5.2.0-Linux-x86_64.sh |
安装完Anaconda之后
1 | $ source ~/.bashrc |
如果Anaconda被成功安装,终端将出现 “Python 2.7.xx :: Anaconda, Inc. “。
9.1.2 ROS 依赖包
首先安装依赖包
1 | $ pip install msgpack argparse |
要同时使用ROS和Anaconda,你必须额外安装ROS的依赖包。
1 | $ pip install -U rosinstall empy defusedxml netifaces |
9.1.3 Tensorflow
本教程使用python 2.7(仅限CPU)。如果你想使用其他python版本和GPU,请参考TensorFlow。
1 | $ pip install --ignore-installed --upgrade https://storage.googleapis.com/tensorflow/linux/cpu/tensorflow-1.8.0-cp27-none-linux_x86_64.whl |
9.1.4 Keras
Keras是一个高级神经网络API,用Python编写,能够在TensorFlow之上运行。
1 | $ pip install keras==2.1.5 |
关于tensorboard的不兼容的错误信息可以忽略,因为在这个例子中没有使用它,但是可以通过安装tensorboard来解决,如下所示。
1 | $ pip install tensorboard |
9.1.5 机器学习软件包
警告。在安装本软件包之前,请先安装turtlebot3、turtlebot3_msgs和turtlebot3_simulations 软件包。
1 | $ cd ~/catkin_ws/src/ |
机器学习是在Gazebo模拟世界上运行的。如果你还没有安装TurtleBot3模拟包,请用下面的命令安装。
1 | $ cd ~/catkin_ws/src/ |
完全卸载并重新安装numpy以纠正问题。你可能需要执行几次卸载,直到numpy被完全卸载。
1 | $ pip uninstall numpy |
在这一点上,numpy应该已经完成卸载,当输入pip show numpy时,你不应该看到任何numpy信息。
重新安装numpy。
1 | $ pip install numpy pyqtgraph |
9.2 设置参数
DQN代理的目标是让TurtleBot3避开障碍物到达目标。当TurtleBot3接近目标时,它就会得到积极的奖励,而当它走得更远时,就会得到消极的奖励。当TurtleBot3在障碍物上坠落或经过一段时间后,该情节就会结束。在这一集里,当TurtleBot3到达目标时,它得到一个很大的积极奖励,而当TurtleBot3撞到障碍物时,它得到一个很大的消极奖励。
电子手册中的内容可能会在没有事先通知的情况下进行更新。因此,一些视频可能与电子手册中的内容有所不同。
9.2.1 设定状态
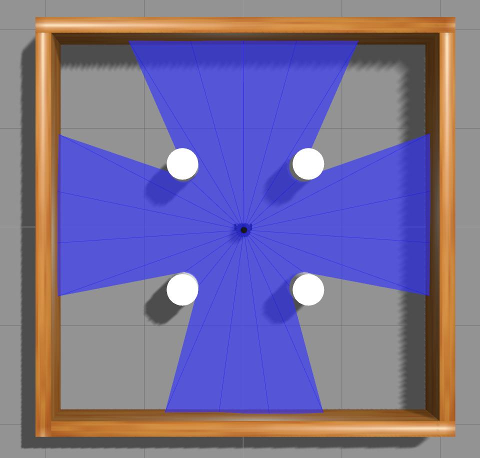
状态是对环境的观察,描述了当前的情况。这里,state_size是26,有24个LDS值,到目标的距离和到目标的角度。
Turtlebot3的LDS默认设置为360。你可以在turtlebot3/turtlebot3_description/urdf/turtlebot3_burger.gazebo.xacro修改LDS的样本。
1 | <xacro:arg name="laser_visual" default="false"/> # Visualization of LDS. If you want to see LDS, set to `true` |
 |
 |
|---|---|
| sample = 360 | sample = 24 |
9.2.2 设置行为
行动是一个代理在每个状态下可以做的事情。这里,Turtlebot3的线速度一直是0.15米/秒。角速度由行动决定。
| Action | Angular velocity(rad/s) |
|---|---|
| 0 | -1.5 |
| 1 | -0.75 |
| 2 | 0 |
| 3 | 0.75 |
| 4 | 1.5 |
9.2.3 设置奖励
当Turtlebot3在某一状态下采取某种行动时,它就会得到奖励。奖励的设计对学习非常重要。奖励可以是积极的或消极的。当Turtlebot3到达目标时,它就会得到巨大的正面奖励。当Turtlebot3与障碍物相撞时,它就会得到很大的负奖励。如果你想应用你的奖励设计,请修改/turtlebot3_machine_learning/turtlebot3_dqn/src/turtlebot3_dqn/environment_stage_#.py的setReward函数。
9.2.4 设置 hyper 参数
本教程是用DQN学习的。DQN是一种强化学习方法,它通过近似动作值函数(Q值)来选择一个深度神经网络。代理人在/turtlebot3_machine_learning/turtlebot3_dqn/nodes/turtlebot3_dqn_stage_#中遵循超参数。
| Hyper parameter | default | description |
|---|---|---|
| episode_step | 6000 | The time step of one episode. |
| target_update | 2000 | Update rate of target network. |
| discount_factor | 0.99 | Represents how much future events lose their value according to how far away. |
| learning_rate | 0.00025 | Learning speed. If the value is too large, learning does not work well, and if it is too small, learning time is long. |
| epsilon | 1.0 | The probability of choosing a random action. |
| epsilon_decay | 0.99 | Reduction rate of epsilon. When one episode ends, the epsilon reduce. |
| epsilon_min | 0.05 | The minimum of epsilon. |
| batch_size | 64 | Size of a group of training samples. |
| train_start | 64 | Start training if the replay memory size is greater than 64. |
| memory | 1000000 | The size of replay memory. |
9.3 运行机器学习
在这个机器学习的例子中,使用了24个激光雷达样本,应该按照设置参数部分的写法来修改。
9.3.1 第一阶段(没有障碍物)
第一阶段是一个没有障碍物的4x4地图。

1 | $ roslaunch turtlebot3_gazebo turtlebot3_stage_1.launch |
打开另一个终端,输入以下命令。
1 | $ roslaunch turtlebot3_dqn turtlebot3_dqn_stage_1.launch |
如果你想看到可视化的数据,请启动 graph。
1 | $ roslaunch turtlebot3_dqn result_graph.launch |
9.3.2 第二阶段(静止障碍物)
第二阶段是一个4x4地图,有四个圆柱形的静态障碍。

1 | $ roslaunch turtlebot3_gazebo turtlebot3_stage_2.launch |
打开另一个终端,输入以下命令。
1 | $ roslaunch turtlebot3_dqn turtlebot3_dqn_stage_2.launch |
如果你想看到可视化的数据,请启动graph。
1 | $ roslaunch turtlebot3_dqn result_graph.launch |
9.3.3 第三阶段(移动障碍物)
第二阶段是一个4x4地图,有四个圆柱形的移动障碍。

1 | $ roslaunch turtlebot3_gazebo turtlebot3_stage_3.launch |
打开另一个终端,输入以下命令。
1 | $ roslaunch turtlebot3_dqn turtlebot3_dqn_stage_3.launch |
如果你想看到可视化的数据,请启动graph。
1 | $ roslaunch turtlebot3_dqn result_graph.launch |
9.3.4 第四阶段(组合障碍)
第四阶段是一张5x5的地图,有墙和两个圆柱形的移动障碍物。

1 | $ roslaunch turtlebot3_gazebo turtlebot3_stage_4.launch |
打开另一个终端,输入以下命令。
1 | $ roslaunch turtlebot3_dqn turtlebot3_dqn_stage_4.launch |
如果你想看到可视化的数据,请启动graph。
1 | $ roslaunch turtlebot3_dqn result_graph.launch |